Análisis de sentimientos en R con 'syuzhet'
{% include toc.html %}
Objetivos
Esta lección utiliza la metodología de análisis de sentimientos y emociones mediante el lenguaje de programación R, para investigar documentos de tipo textual de forma individual. Aunque la lección no está pensada para usuarios avanzados de R, es necesario que cuentes con ciertos conocimientos de dicho lenguaje; asumimos que tienes R instalado y sabes cómo cargar paquetes. También recomendamos la descarga de R Studio. Si no estás familiarizado con R, es mejor trabajar primero con las lecciones Procesamiento básico de textos en R, Datos tabulares en R o Administración de datos en R. Al final de esta lección podrás:
- Plantear preguntas de investigación basadas en análisis cuantitativo de sentimientos en textos de tipo ensayístico y/o narrativo
- Usar el lenguaje de programación R, el entorno R Studio y el paquete
syuzhetcon el diccionario NRC para generar el valor sentimental y emocional de un texto en diferentes idiomas - Analizar críticamente los resultados del procesamiento de texto
- Visualizar los datos generales y su evolución a lo largo de un texto
Esta lección fue construida con la versión 4.0.2 de R, pero creemos que funcionará correctamente en versiones futuras del programa.
La utilización de R es, en general, la misma para Windows, Mac y Linux. Sin embargo, como vamos a trabajar con textos en español, necesitaremos escribir algo de código extra para indicar el formato UTF-8 en máquinas Windows. En dichos casos, se despliega el código para el sistema operativo correspondiente.
Antes de empezar
Análisis de sentimientos
El análisis de sentimientos o la minería de opinión es utilizado para extraer de forma automática, información sobre la connotación negativa o positiva del lenguaje de un documento. Aunque es una tarea que lleva tiempo siendo utilizada en el campo del marketing o la política, en los estudios literarios es un acercamiento todavía reciente y sobre el que no hay un único método. Además, existe la posibilidad de extraer la polaridad de los sentimientos pero también de las emociones.
Conviene especificar qué se busca con los términos de sentimiento y de emociones, ya que se suelen utilizar indistintanmente de forma general pero son diferentes. Para Antonio R. Damasio, las emociones son reacciones corporales institivas de nuestro cuerpo, determinadas por estímulos medioambientales y derivadas del desarrollo de regulación biológica (12). Estas pueden dividirse en primarias y secundarias. Aunque no hay un acuerdo final sobre el número de emociones básicas, se suele hablar de seis, siendo estas el enfado o la ira, la alegría, el disgusto o asco, el miedo, la tristeza y la sorpresa, aunque para Damasio esta última es secundaria. Además, en el caso del sistema automático que utilizaremos, también se ofrece la aparición de las emociones secundarias de la anticipación y la confianza.
Por otro lado, podemos definir el sentimiento como la acción y efecto de sentir una emoción o, dicho de otro modo, es el resultado de que "cuando un objeto, una persona, una situación, o un pensamiento provoca en nosotros la emoción de la alegría, comienza un proceso que puede concluir en el sentimiento de estar alegres o felices" (Pereira Zazo 32) por ser una emoción positiva. Durante la lección haremos una distinción entre ambos términos, ya que se utilizará el resultado del sentimiento para ver su evolución a lo largo del texto y las emociones para ver el uso de palabras en general.
Diccionario de léxico NRC
El paquete syuzhet trabaja con cuatro diccionarios de sentimientos: Bing, Afinn, Stanford y NRC. En esta lección trabajaremos con este último puesto que es el único disponible en varios idiomas, incluido el español. Este vocabulario con valores de sentimiento negativo o positivo y ocho emociones ha sido desarrollado por Saif M. Mohammad, científico del Consejo de Investigación Nacional de Canadá (NRC por sus siglas en inglés). El conjunto de datos ha sido anotado manualmente mediante encuestas con la técnica de Escalamiento por Máxima Diferencia o MaxDiff, que evalúa la preferencia en una serie de alternativas (Mohammad y Turney). Así, el léxico cuenta con 14,182 unigramas (palabras) con las categorías de sentimientos positivo y negativo y las emociones de enfado, anticipación, disgusto, miedo, alegría, tristeza, sorpresa y confianza. Además, está disponible en más de cien idiomas (mediante traducción automática).
Sus términos de uso indican que el vocabulario puede ser utilizado de forma gratuita con propósitos de investigación, por lo que todos los datos están disponible para su descarga.
Si sabes inglés, puedes interactuar con las diferentes categorías en su página web NRC Word-Emotion Association Lexicon. En ella también puedes encontrar trabajos publicados sobre la obtención de los valores para el vocabulario, su organización, ampliación, etc.
Paquete syuzhet
El paquete de R syuzhet fue desarrollado en 2015 por Matthew Jockers; continuamente introduce cambios y se encarga de mantenerlo (al momento de preparar esta lección se usó la versión de diciembre 2017). Una serie de entradas de blog acompañan el desarrollo del paquete, y pueden consultarse (en inglés) en el blog del profesor desde el 5 de junio de 2014.
Por descontado, el paquete ha sido desarrollado con pruebas en textos escritos o traducidos al inglés y no sin debate sobre su utilidad, por asignar valores a textos literarios que suelen ser, por naturaleza, bastante subjetivos.
Advertencias: El listado de palabras en el diccionario está siendo preparado en inglés como lenguaje principal y los datos cuantitativos asignados a cada unigrama es el resultado de una valoración humana por parte de participantes estadounidenses. Por tanto, debes tener en cuenta varios factores a la hora de usar esta metodología:
- El léxico en español es una traducción directa realizada por traducción automática (estos sistemas son ya muy fiables entre inglés y español, pero no así en otras lenguas que NRC dice poder analizar como, por ejemplo, el euskera)
- La puntuación de cada palabra, es decir, la valencia sentimental y emocional, tiene un sesgo cultural y temporal que debes tener en cuenta y un término que a los participantes en la encuesta les pareciera positivo a ti puede parecerte negativo
- No se recomienda el uso de esta metodología en textos con gran carga metafórica y simbólica
- El método no captará la negación de un sentimiento positivo como, por ejemplo, la frase "no estoy feliz"
Siguiendo el espíritu de adaptabilidad de las lecciones de Programming Historian a otros idiomas, se ha decidido utilizar
syuzheten su forma original, pero al final de la lección indicamos algunas funciones avanzadas para utilizar tu propio diccionario de sentimientos con el mismo paquete.
Puesto que los resultados en los dataframes van a aparecer en inglés, en caso que lo consideres necesario toma un momento para aprender esta traducción:
| anger | anticipation | disgust | fear | joy | sadness | surprise | trust | negative | positive |
|---|---|---|---|---|---|---|---|---|---|
| enfado | anticipación | disgusto | miedo | alegría | tristeza | sorpresa | confianza | negativo | positivo |
Un pequeño ejemplo
Antes de empezar a realizar el análisis en nuestros textos, conviene saber de forma general cuál es el proceso de análisis llevado a cabo por la función de obtener sentimentos de syuzhet, con el diccionario NRC y los resultados obtenidos sobre los que trabajaremos.
El sistema procesará nuestro texto y lo transformará en un vector de caracteres (aquí palabras), para analizarlos de forma individual (también es posible hacerlo por oraciones). Sin entrar todavía en el código para realizar el análisis, observa este breve ejemplo:
Retumbó el disparo en la soledad de aquel abandonado y tenebroso lugar; Villaamil, dando terrible salto, hincó la cabeza en la movediza tierra, y rodó seco hacia el abismo, sin que el conocimiento le durase más que el tiempo necesario para poder decir: «Pues... sí...».
Miau de Benito Pérez Galdós.
Dicho fragmento se transforma en un vector de caracteres:
> ejemplo
[1] "retumbó" "el" "disparo" "en" "la" "soledad"
[7] "de" "aquel" "abandonado" "y" "tenebroso" "lugar"
[13] "villaamil" "dando" "terrible" "salto" "hincó" "la" ...
Con la función de obtener sentimientos se obtiene la valencia positiva y negativa de cada unigrama, así como la valencia de las ocho emociones clasificadas por NRC. El resultado para este fragmento es el siguiente:
> print(ejemplo_2, row.names = ejemplo)
anger anticipation disgust fear joy sadness surprise trust negative positive
retumbó 0 0 0 0 0 0 0 0 0 0
el 0 0 0 0 0 0 0 0 0 0
disparo 3 0 0 2 0 2 1 0 3 0
en 0 0 0 0 0 0 0 0 0 0
la 0 0 0 0 0 0 0 0 0 0
soledad 0 0 0 2 0 2 0 0 2 0
de 0 0 0 0 0 0 0 0 0 0
aquel 0 0 0 0 0 0 0 0 0 0
abandonado 2 0 0 1 0 2 0 0 3 0
y 0 0 0 0 0 0 0 0 0 0
tenebroso 0 0 0 0 0 0 0 0 0 0
lugar 0 0 0 0 0 0 0 0 0 0
villaamil 0 0 0 0 0 0 0 0 0 0
dando 0 0 0 0 0 0 0 0 0 1
terrible 2 1 2 2 0 2 0 0 2 0
salto 0 0 0 0 0 0 0 0 0 0
hincó 0 0 0 0 0 0 0 0 0 0
la 0 0 0 0 0 0 0 0 0 0
...
Como vemos en los resultados de este objeto de tipo data frame o tabla, cada palabra o token cuenta con valor 0 por defecto en las diez columnas. Si hay un valor mayor a 0 quiere decir, primero, que dicho término existe en el diccionario NRC y, segundo, que tiene un valor asignado para alguna emoción y/o sentimiento. En este ejemplo podemos observar que las palabras "disparo", "soledad", "abandonado", "terrible", "abismo" y "necesario", tienen una carga negativa, mientras que "dando", "tierra" y "conocimiento", son consideradas palabras positivas. También podemos fijarnos en que la palabra "disparo" reporta emociones de enfado (anger), miedo (fear), tristeza (sadness) y sorpresa (surprise).
Las posibilidades de la exploración, el análisis y la visualización de estos resultados dependen en gran medida de tus habilidades de programación pero, sobre todo, de tu pregunta de investigación. Para ayudarte, en esta lección introductoria aprenderemos a analizar los datos mediante varias formas de visualización.
Pregunta de investigación
Para esta lección vamos a utilizar la novela Miau de Benito Pérez Galdós, publicada en 1888. De género realista y enmarcada en sus Novelas españolas contemporáneas, la novela transcurre en el Madrid de finales del siglo XIX y satiriza la administración del ministerio de la época. En una especie de tragicomedia, asistimos a los últimos días de Ramón Villaamil tras quedar desempleado, mientras su familia estira el escaso presupuesto en pretender ser pudiente. La espiral de mala fortuna e imposibilidad de encontrar un nuevo empleo termina en tragedia.
¿Podemos observar la caída emocional de esta trama al extraer de forma automática los valores de sentimientos de la novela? O, en otras palabras, ¿coincide nuestra recepción del transcurrir de Villaamil con los resultados de un cómputo automático? Además, ¿qué palabras son más utilizadas en la descripción de las emociones del texto?
Obtener valores de sentimientos y emociones
Instalar y cargar paquetes
Lo primero que debemos hacer para poder llevar a cabo la obtención de los sentimientos de nuestro texto, es instalar y cargar el paquete de R correspondiente, en este caso, syuzhet. Además, para facilitar la visualización de los datos vamos a utilizar los paquetes RColorBrewer, wordcloud, tm y NLP. Para ello escribe y ejecuta los siguientes dos comandos en tu consola; el primero para instalar el paquete y el segundo para cargarlo (si ya tienes alguno instalado, solo hace falta que lo cargues). Ten en cuenta que la instalación de estos paquetes puede tomar unos minutos.
# Instala los paquetes:
install.packages("syuzhet")
install.packages("RColorBrewer")
install.packages("wordcloud")
install.packages("tm")
# Carga los paquetes
library(syuzhet)
library(RColorBrewer)
library(wordcloud)
library(tm)
Cargar y preparar el texto
Descarga el texto de la novela Miau. Como puedes ver, el documento está en formato de texto plano, al ser esto imprescindible para llevar a cabo su procesamiento y análisis en R.
Con el texto a mano, lo primero que vamos a hacer es cargarlo como una cadena de caracteres en un objeto de tipo cadena (string). Asegúrate de cambiar la ruta al texto para que corresponda con tu computadora.
En Mac y Linux
En los sistemas Mac podemos usar la función get_text_as_string integrada en el paquete syuzhet:
texto_cadena <- get_text_as_string("https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/galdos_miau.txt")
En Windows
Los sistemas Windows no leen directamente los caracteres con tildes u otras marcas propias del español, el portugués o el francés, así que tenemos que indicarle al sistema que nuestro texto está en formato UTF-8 mediante la función scan.
texto_cadena <- scan(file = "https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/galdos_miau.txt", fileEncoding = "UTF-8", what = character(), sep = "\n", allowEscapes = T)
Puesto que el análisis que vamos a realizar necesita de un listado, ya sea de palabras u oraciones(aquí solo prestaremos atención a las palabras individuales), necesitamos un paso intermedio entre la carga del texto y la extracción de los valores de sentimientos. Así, vamos a dividir la cadena de caracteres en un listado de palabras o unigramas (tokens). Esto es algo muy habitual en el análisis distante de textos.
Para esto utilizamos la función get_tokens() del paquete y generamos un nuevo objeto, en este caso un vector de unigramas. Como verás, con esta función nos hemos deshecho de la puntuación en el texto y tenemos una lista de palabras.
texto_palabras <- get_tokens(texto_cadena)
head(texto_palabras)
[1] "miau" "por" "b" "pérez" "galdós" "14"
Ahora podemos ver cuántas palabras o tokens hay en este texto con la función length():
length(texto_palabras)
[1] 97254
Si quieres realizar el análisis por oraciones, utiliza la función get_sentences() y sigue el mismo proceso excepto la creación de nube de palabras:
oraciones_vector <- get_sentences(texto_cadena)
length(oraciones_vector)
[1] 6022
Extracción de datos con el Léxico de Sentimientos NRC
Ahora ya podemos ejecutar la función get_nrc_sentiment para obtener los sentimientos en la novela Miau. Ahora bien, puesto que la función ejecuta por defecto el vocabulario en inglés, nosotros le indicamos con el argumento "lang" (de language) que utilice el vocabulario en español ("spanish"). A su vez, creamos un nuevo objeto para almacenar los datos extraidos. Esto será un objeto de tipo data frame. Esta función busca la presencia de las ocho emociones y los dos sentimientos para cada palabra en nuestro vector, y asigna un número mayor a 0 en caso de existir. Dependiendo de las prestaciones de tu computadora y de acuerdo con las características de nuestro texto, este proceso puede tardar entre 15 y 30 minutos.
sentimientos_df <- get_nrc_sentiment(texto_palabras, lang="spanish")
Al terminarse de ejecutar el código, aparecerá una advertencia debido a que syuzhet utiliza una función que está discontinuada dentro de su función get_nrc_sentiment.
Warning message:
`data_frame()` is deprecated as of tibble 1.1.0.
Please use `tibble()` instead.
This warning is displayed once every 8 hours.
Call `lifecycle::last_warnings()` to see where this warning was generated.
Cuando el proceso termina, si lo deseas, puedes leer los resultados en el nuevo objeto simplemente seleccionando el objeto y ejecutándolo. Pero para evitar "imprimir" miles de líneas en la consola, también puedes usar la función head() para ver los primeros seis unigramas. En el caso del texto que estamos utilizando, al ejecutar dicha función deberías ver lo siguiente, lo cual no es nada interesante:
> head(sentimientos_df)
anger anticipation disgust fear joy sadness surprise trust negative positive
1 0 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0 0 0
Resumen del texto
Lo que sí es interesante, es ver un resumen de cada uno de los valores que hemos obtenido mediante la función general summary(). Esto puede ser muy útil a la hora de comparar varios textos, pues te permite ver diferentes medidas, como es el caso de la media de los resultados de cada una de las emociones y los dos sentimientos. Por ejemplo, podemos ver que la novela Miau es, de media (mean), más positiva (0.05153) que negativa (0.04658). Pero si nos fijamos, parece que en las emociones la tristeza (0.02564) aparece en más momentos que la alegría (0.01929). Como ves, varios de los valores proporcionados por la función de resumen del texto aparecen con un valor igual a 0, incluyendo la mediana (median). Esto indica que en el diccionario que estamos utilizando (NRC) aparecen pocas de las palabras en la novela o, al revés, que pocas de las palabras cuentan con una asignación de sentimiento o emoción en el diccionario.
> summary(sentimientos_df)
anger anticipation disgust fear
Min. :0.00000 Min. :0.00000 Min. :0.00000 Min. :0.00000
1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.00000
Median :0.00000 Median :0.00000 Median :0.00000 Median :0.00000
Mean :0.01596 Mean :0.02114 Mean :0.01263 Mean :0.02243
3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:0.00000
Max. :5.00000 Max. :3.00000 Max. :6.00000 Max. :5.00000
joy sadness surprise trust
Min. :0.00000 Min. :0.00000 Min. :0.00000 Min. :0.00000
1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.00000
Median :0.00000 Median :0.00000 Median :0.00000 Median :0.00000
Mean :0.01929 Mean :0.02564 Mean :0.01035 Mean :0.03004
3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:0.00000
Max. :5.00000 Max. :7.00000 Max. :2.00000 Max. :3.00000
negative positive
Min. :0.00000 Min. :0.00000
1st Qu.:0.00000 1st Qu.:0.00000
Median :0.00000 Median :0.00000
Mean :0.04658 Mean :0.05153
3rd Qu.:0.00000 3rd Qu.:0.00000
Max. :7.00000 Max. :5.00000
¡Felicidades! Ya tienes los resultados del análisis de sentimientos. Ahora, ¿qué podemos hacer con estos números?
Análisis de las emociones de un texto
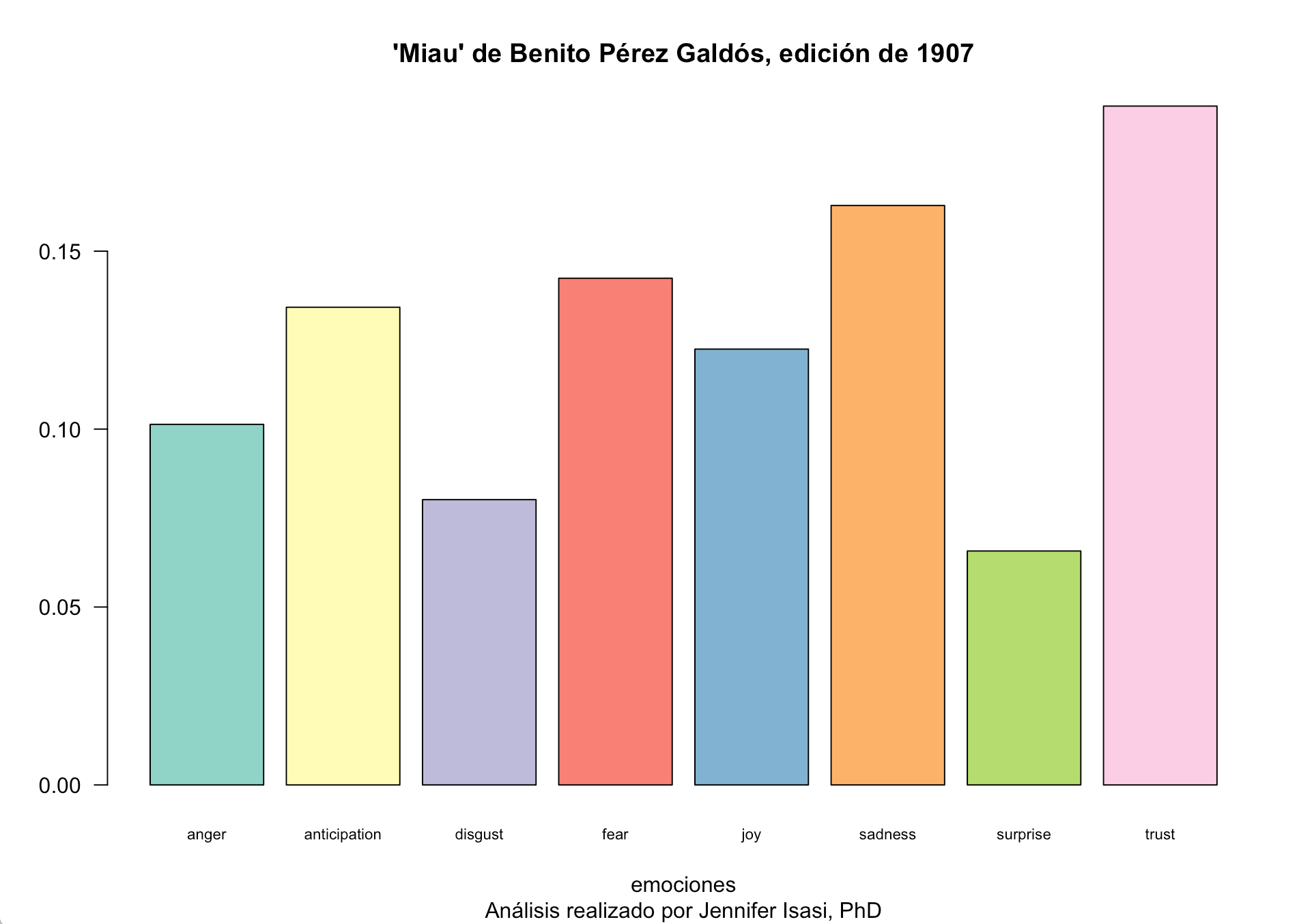
Gráfico de barras
Para ver cuáles son las emociones con mayor presencia en el texto, lo más simple es crear un gráfico de barras. Para ello utilizamos la función barplot() con el resumen de las columnas 1 a 8, es decir, las columnas de enfado (anger), anticipación (anticipation), disgusto (disgust), miedo (fear), alegría (joy), tristeza (sadness), sorpresa (surprise) y confianza (trust). Los resultados obtenidos provienen del procesado que hace la función prop.table() con los resultados de las ocho columnas con cada una de las palabras en la tabla.
Para cada barra se suman todos los valores de la columna de la emoción correspondiente. A continuación, se suma el resultado de todas las emociones que añadamos en la salida del gráfico. Al final, se divide la suma de cada emoción entre el total de todas las columnas o emociones. Esto no añade las columnas de negativo y positivo. [^1]
barplot(
colSums(prop.table(sentimientos_df[, 1:8])),
space = 0.2,
horiz = FALSE,
las = 1,
cex.names = 0.7,
col = brewer.pal(n = 8, name = "Set3"),
main = "'Miau' de Benito Pérez Galdós, edición de 1907",
sub = "Análisis realizado por Jennifer Isasi, PhD",
xlab="emociones", ylab = NULL)
El resto de parámetros que ves en el código son "extras", en tanto que son una forma de configurar el formato visual del gráfico. Así, indicamos un espacio (space) de 0.2 entre las barras, que irán en posición vertical al indicar en falso (FALSE) su horizontalidad (horiz) y, al contrario, la horizontalidad para los valores en el eje Y con las = 1. Además, reducimos el tamaño del nombre de cada barra (cex.names) a 0.7 para evitar que desaparezcan, por ejemplo, si hacemos un gráfico pequeño. Gracias al paquete que hemos instalado al principio, RColorBrewer, podemos dar color a las columnas de forma automática, en este caso, con la paleta colores (brewer.pal) del set número 3 del paquete, con ocho colores, uno para cada columna. Finalmente, vamos a poner un título y subtítulo a nuestro gráfico con los parámetros mainy sub, así como la palabra "emociones" en el eje X y nada en el Y.
Si no te interesan estos parámetros, sería suficiente ejecutar lo siguiente para obtener el gráfico por defecto:
barplot(colSums(prop.table(sentimientos_df[, 1:8])))
Asegúrate de tener suficiente espacio en el bloque de visualización de gráficos en R para poder ver los nombres de cada columna.
Esta información ya nos indica que las emociones de tristeza y miedo son más prevalentes que la emoción de asco o de sorpresa. Pero, ¿qué palabras son utilizadas por Galdós en la expresión de ese miedo? ¿con qué frecuencia aparece cada una en el conjunto de la novela?
Recuento de palabras con cada emoción
Para realizar un análisis de texto, es muy interesante conocer qué palabras son usadas con mayor frecuencia en el texto en relación a su identidicación con cada emoción. Para ello primero tenemos que crear un objecto de caracteres con todas las palabras que tengan un valor superior a 0 en la columna de "tristeza" (sadness). Para seleccionar solo esa columna usamos el símbolo de dólar después del nombre del data frame:
palabras_tristeza <- texto_palabras[sentimientos_df$sadness> 0]
Como puedes observar por el contenido de palabras_tristeza este listado no nos dice mucho, pues solamente nos ofrece el listado de palabras sin mayor información. Para obtener el recuento de veces que cada palabra relacionada con la tristeza aparece en la novela, generamos una tabla del primer conjunto de caracteres con las funciones unlist y table, que luego ordenamos en order decreciente (si se quiere un orden ascendiente cambiamos TRUE a FALSE); creamos un nuevo objeto de tipo tabla e imprimimos las 12 primeras palabras del listado con su frecuencia:
palabras_tristeza_orden <- sort(table(unlist(palabras_tristeza)), decreasing = TRUE)
head(palabras_tristeza_orden, n = 12)
muy nada pobre tarde
271 156 64 58
mal caso malo salir
57 50 39 35
madre insignificante ay culpa
33 29 24 22
Si quisierámos conocer cuántas palabras únicas han sido relacionadas con la tristeza, basta utilizar la función length sobre el objeto que ahora agrupa las palabras en orden:
length(palabras_tristeza_orden)
[1] 349
Podemos repetir la misma operación con el resto de emociones o con la que nos interese, además de con los sentimientos positivos y negativos. Trata de obtener los resultados de la emoción "alegría" y compara los resultados.[^2]
Dependiendo del tipo de análisis que quieras hacer, dicho resultado es eficiente. Ahora, para el propósito introductorio de la lección, vamos a generar una nube de palabras que ayuda a visualizar fácilmente los términos asociados con cada emoción (aunque solo visualizaremos aquí cuatro para facilitar su lectura).
Nube de emociones
Para poder crear una nube con las palabras que corresponden a cada emoción en Miau vamos a crear primero un vector en el que se guardan todas la palabras que, en las columnas que indicamos tras el símbolo $ tienen un valor mayor a 0. Se genera un nuevo objeto de tipo vector, que contiene un elemento para el listado de cada emoción.
En este caso debemos indicar de nuevo a la función que tenemos caracteres acentuados si se trata de una máquina Windows.
En Mac y Linux
nube_emociones_vector <- c(
paste(texto_palabras[sentimientos_df$sadness> 0], collapse = " "),
paste(texto_palabras[sentimientos_df$joy > 0], collapse = " "),
paste(texto_palabras[sentimientos_df$anger > 0], collapse = " "),
paste(texto_palabras[sentimientos_df$fear > 0], collapse = " "))
En Windows
Una vez generado el vector, debes convertirlo (iconv) en caracteres en UTF-8.
nube_emociones_vector <- c(
paste(texto_palabras[sentimientos_df$sadness> 0], collapse = " "),
paste(texto_palabras[sentimientos_df$joy > 0], collapse = " "),
paste(texto_palabras[sentimientos_df$anger > 0], collapse = " "),
paste(texto_palabras[sentimientos_df$fear > 0], collapse = " "))
nube_emociones_vector <- iconv(nube_emociones_vector, "latin1", "UTF-8")
Una vez que tenemos el vector creamos un corpus de palabras con cuatro "documentos" para la nube:
nube_corpus <- Corpus(VectorSource(nube_emociones_vector))
A continuación, transformamos dicho corpus en una matriz término-documento con la función TermDocumentMatrix(). Con ello, utilizamos ahora la función as.matrix() para convertir el TDM a una matriz que, como podemos ver, cuenta con el listado de los términos del texto con un valor mayor a cero para cada una de las cuatro emociones que aquí hemos extraído. Para ver el inicio de esta información vuelve a utilizar la función head:
nube_tdm <- TermDocumentMatrix(nube_corpus)
nube_tdm <- as.matrix(nube_tdm)
head(nube_tdm)
Docs
Terms 1 2 3 4
abandonado 4 0 4 0
abandonar 1 0 0 0
abandonará 2 0 0 0
abandonaré 1 0 0 0
abandonarías 1 0 0 0
abandono 3 0 3 0
Ahora, asigna un nombre a cada uno de los grupos de palabras o documentos (Docs) en nuestra matriz. Aquí vamos a utilizar el término en español para las columnas que hemos seleccionado para visualizar en la nube. De nuevo, puedes ver el cambio realizado al ejecutar la función head.
colnames(nube_tdm) <- c('tristeza', 'felicidad', 'enfado', 'confianza')
head(nube_tdm)
Docs
Terms tristeza felicidad enfado confianza
abandonado 4 0 4 4
abandonar 1 0 0 1
abandonará 2 0 0 2
abandonaré 1 0 0 1
abandonarías 1 0 0 1
abandono 3 0 3 3
Finalmente, podemos visualizar la nube de palabras a la que ya estamos acostumbrados a ver en los medios o en estudios académicos. El tamaño y localización de la palabra corresponde a su mayor o menor aparición con valor de emoción asignado en el texto. Primero ejecutamos la función set.seed() para que al reproducir el resultado visual sea igual al nuestro (si no lo haces, saldrá lo mismo pero aparecerán las palabras en diferentes posiciones). Y para generar la nube, vamos a utilizar la función comparison.cloud del paquete wordcloud. Señalamos el objeto a representar, aquí 'nube_tdm', indicamos un orden no aleatorio de las palabras, asignamos un color para cada grupo de palabras y damos tamaños al título, la escala general y asignamos un número máximo de términos que serán visualizados.
set.seed(757) # puede ser cualquier número
comparison.cloud(nube_tdm, random.order = FALSE,
colors = c("green", "red", "orange", "blue"),
title.size = 1, max.words = 50, scale = c(2.5, 1), rot.per = 0.4)
Deberías obtener una imagen similar a la siguiente, aunque con la localización de las palabras alterada pues se genera según el tamaño del canvas o lienzo.
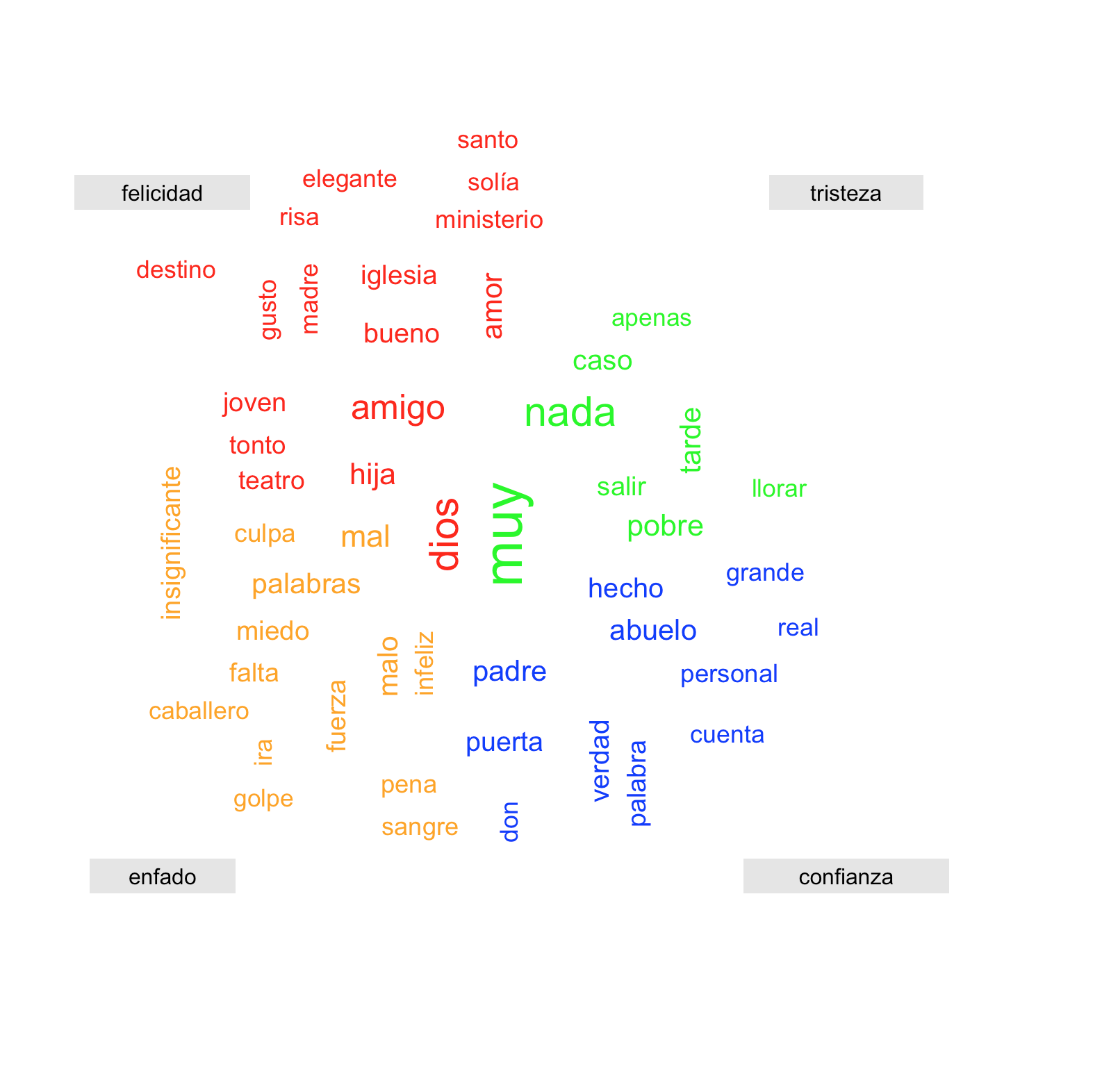
¿Qué te sugiere el resultado de esta nube? Seguramente te llamará la atención la aparición del adverbio "muy" en el conjunto de tristeza o el sustantivo "dinero" en el conjunto de enfado. Este "sinsentido" está relacionado con la advertencia ya anunciada al comienzo de la lección. El vocabulario para el análisis de sentimientos que estamos utilizando aquí está traducido del inglés mediante un traductor automático y no es "perfecto".
Visualizar la evolución de sentimientos en el texto
Para complementar la lectura aislada de las emociones mediante el estudio de la fluctuación de los sentimientos positivos y negativos a lo largo de un texto, existe una manera de normalizar y visualizar dicha información. Puesto que el análisis de la función de extracción de los sentimientos asigna un valor positivo tanto al sentimiento positivo como al negativo, necesitamos generar datos entre un rango de -1 para el momento más negativo y 1 para el más positivo, y donde 0 sea neutral. Para ello calculamos la valencia del texto multiplicando los valores de la columna de valores negativos de nuestro data frame, con los resultados por -1 y sumamos el valor de la columna de valores positivos.
sentimientos_valencia <- (sentimientos_df$negative *-1) + sentimientos_df$positive
Finalmente, podemos generar un gráfico con la función simple_plot() integrada en el paquete syuzhet que nos ofrecerá dos imágenes diferentes; la primera tiene todas las medidas que el algoritmo calcula y la segunda es una normalización de las mismas. El eje horizontal presenta el texto en 100 fragmentos normalizados y el eje vertical nos informa de la valencia del sentimiento en el texto. Dependiendo de las características de tu computadora, este gráfico puede tomar hasta 20-30 minutos en generarse.
simple_plot(sentimientos_valencia)
Asegúrate de tener suficiente espacio en el bloque de visualización de gráficos en R para que se genere el gráfico. De no hacerlo, verás el error: Error in plot.new() : figure margins too large
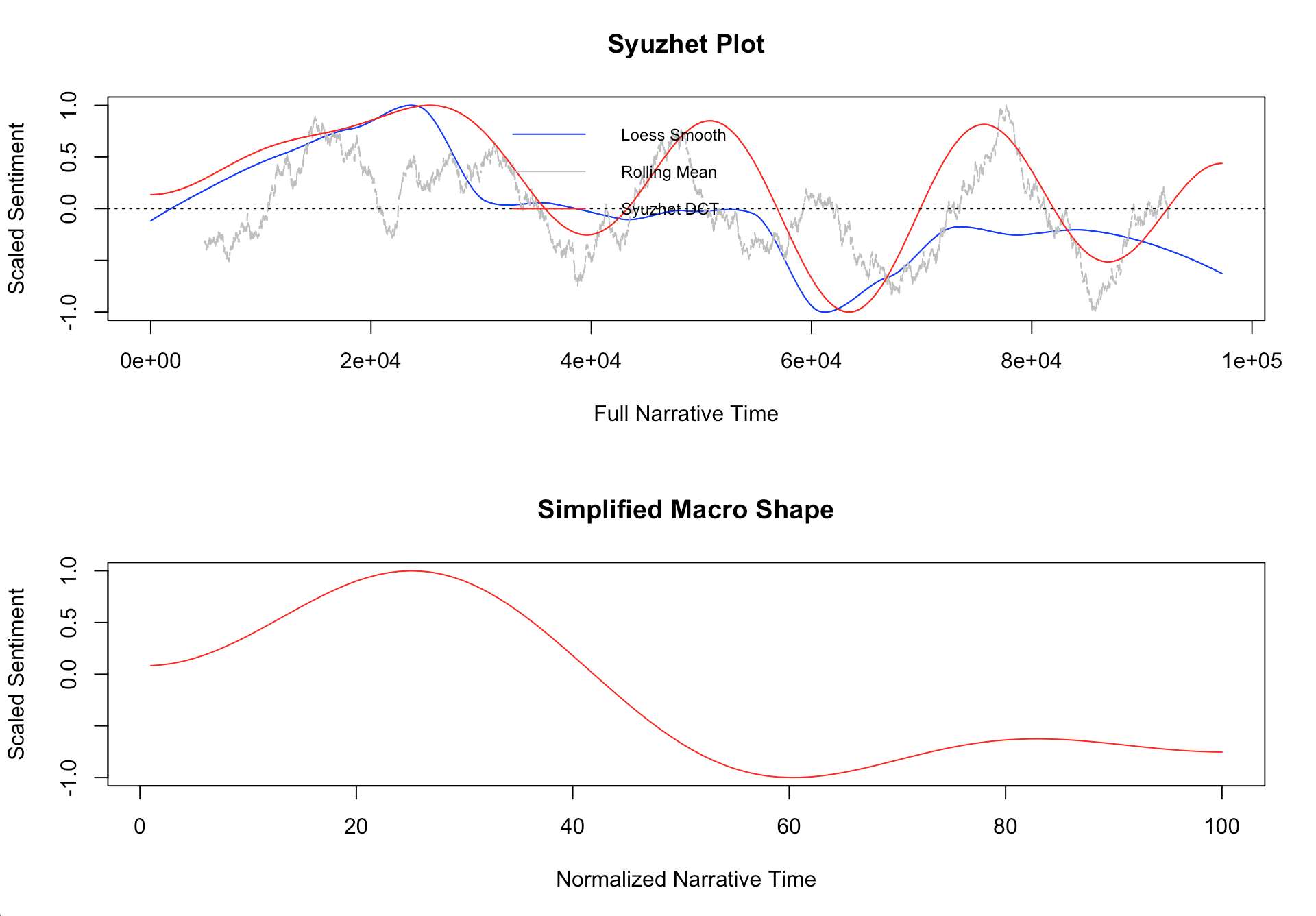
Así, en este caso podemos interpretar que la novela Miau comienza de forma neutral, continúa con algunos momentos alegres durante la primera parte, nos encontramos con situaciones negativas en el resto de la novela, y finaliza de manera negativa, tal como lo indica la oración que utilizamos al comienzo de la lección. Cualquiera que haya leído la novela puede corroborar esta sensación de desesperación por parte del protagonista.
Guarda tus datos
Si quieres guardar los datos para volver a ellos más adelante, puedes hacerlo en un archivo de valores separados por comas (CSV) con la función write.csv(). Aquí le indicamos que debe guardar el data frame, que contiene el resultado de las ocho emociones y los dos sentimientos del texto en un archivo con extensión .csv. Además, podemos añadir la palabra a la que corresponde cada fila de resultados, en una columna a la izquierda utilizando el vector de palabras realizado al comienzo del análisis.
write.csv(sentimientos_df, file = "analisis_sent_miau.csv", row.names = texto_palabras)
¡Ahora ya puedes empezar a analizar tus propios textos y compararlos entre ellos!
Otras funcionalidades y sus limitaciones
A lo mejor estás trabajando en un proyecto en el que, tal vez ya tienes un diccionario de sentimientos creado, o bien, te es necesario personalizar el vocabulario y su valencia sentimental por motivos de cultura o temporalidad, o quizás buscas mejorar los resultados traducidos automáticamente del NRC aquí utilizado. En cualquiera de estos casos, desde finales de 2020 también puedes cargar tu propio conjunto de datos en el script gracias a la función custom y realizar algunas de las operaciones que has aprendido en esta lección.
Para cargar tu propio "diccionario de sentimientos" tienes que, primero, crear (o modificar) un dataframe que contenga, como mínimo, una columna para las palabras y otra para su valencia, por ejemplo:
| word | value |
|---|---|
| amor | 1 |
| cólera | -1 |
| alfombra | 0 |
| catástrofe | -2 |
A continuación, carga tus datos guardados como CSV con la función read.csv, lo que creará un nuevo conjunto disponible como "data.frame", sobre el que ahora podrás contrastar tu texto:
vocabulario_personalizado <- read.csv("archivo.csv")
method <- "custom"
sentimientos_oraciones <- get_sentiment(oraciones_vector, method = method, lexicon = vocabulario_personalizado)
Si quieres visualizar el progreso de los sentimientos a lo largo de tu texto, puedes utilizar la función plot con otros parámetros que ya has aprendido:
plot(sentimientos_oraciones,
type = "l",
main = "'Miau' de Benito Pérez Galdós, edición de 1907",
sub = "Análisis realizado por Jennifer Isasi, PhD",
xlab="emociones", ylab = " "
)
Ahora bien, ten en cuenta que esta forma de análisis se verá limitada y no podrás realizar las mismas operaciones que explicamos más arriba. Por ejemplo, siguiendo el modelo del ejemplo, no tendrías información de las emociones, por lo que no podrás hacer una nube de palabras.
Referencias
Jockers, Matthew L. Syuzhet: Extract Sentiment and Plot Arcs from Text, 2015. https://github.com/mjockers/syuzhet
Jockers, Matthew L. "Introduction to the Syuzhet Package", CRAN R Project, 2017. https://mran.microsoft.com/snapshot/2017-12-31/web/packages/syuzhet/vignettes/syuzhet-vignette.html
Damasio, Antonio R. El error de Descartes: La razón de las emociones. Barcelona: Andres Bello, 1999.
Mohammad, Saif, and Peter D. Turney. "Crowdsourcing a Word–Emotion Association Lexicon". Computational intelligence 29 (2013): 436-465, doi: 10.1111/j.1467-8640.2012.00460.x
Pérez Galdós, Benito. Miau. Madrid: Sucesores de Hernando, 1907.
Pereira Zazo, Óscar. El analisis de la comunicación en español. Iowa: Kendal Hunt, 2015.
Rodríguez Aldape, Fernando Manuel. Cuantificación del Interés de un usuario en un tema mediante minería de texto y análisis de sentimiento. Tesis de maestría, Universidad Autónoma de Nuevo León, 2013.
Notas
[^1]:Gracias a Mounika Puligurthi, estudiante en prácticas en la oficina de Digital Scholarship de la Universidad de Texas (UT) (durante la primavera de 2019), por su ayuda a comprender este cálculo. [^2]:Hay más palabras asignadas a la emoción de tristeza que de alegría tanto en número de palabras totales (2061 frente a 1552) como a palabras únicas (349 frente a 263). Fíjate que la palabra "madre" aparece en ambas emociones con un valor de 33 puntos en ambos casos, ¿qué crees que esto puede significar?